Up to now, I’ve been using Ollama as my platform to research the requirements for processing massive amounts of Intel Processor Trace. But it now seems that I’ll need a more sophisticated development environment to accomplish the model fine-tuning I need to do; so, I’ve switched over to Hugging Face.
In Part 1 and Part 2 of this article series, I worked with the Ollama framework. Those who are familiar with both Ollama and Hugging Face can skip this part: the main difference between the two is that Ollama is a runtime environment for running models locally, while Hugging Face is a collaborative hub for building and sharing AI assets. And since I plan to open-source this work, and Ollama seems more limited in its ability to customize my model, I’m more inclined to work with Hugging Face. A good comparison table is here:
Feature
Ollama
Hugging Face
Primary Role
A local runtime for LLMs
A hub for models, datasets, and tools
Data Privacy
Excellent (all data stays local)
Cloud-based services may process data in the cloud
Latency
Extremely low (no network overhead)
Varies, dependent on network and server load
Scalability
Limited to your local hardware
Virtually unlimited via cloud services
Model Access
A curated list of popular models
Thousands of models across all modalities
Customization
Via simple Modelfile syntax
Via code using libraries like PEFT
Relationship
Often used together. Ollama can pull models from the Hugging Face Hub (GGUF format) and run them locally.
The source for most models that Ollama runs.
Again, I used Tech with Tim’s work as a foundation for this research. It’s really an excellent channel, one of the better ones on YouTube. Have a look at the following links as references:
Hugging Face uses the Transformers Python library to work with its models. As with Ollama, you can download these models to your local computer and run them on your own hardware – subject to the VRAM requirements that I referred to in Part 1. Also, the LangChain Python library provides some advanced features that I’ll need. Finally, the PyCharm application makes working in this environment so much easier. Let’s walk through the steps, and I’ll explain how all these fit together.
The first step is to create a userid on Hugging Face. Simple enough.
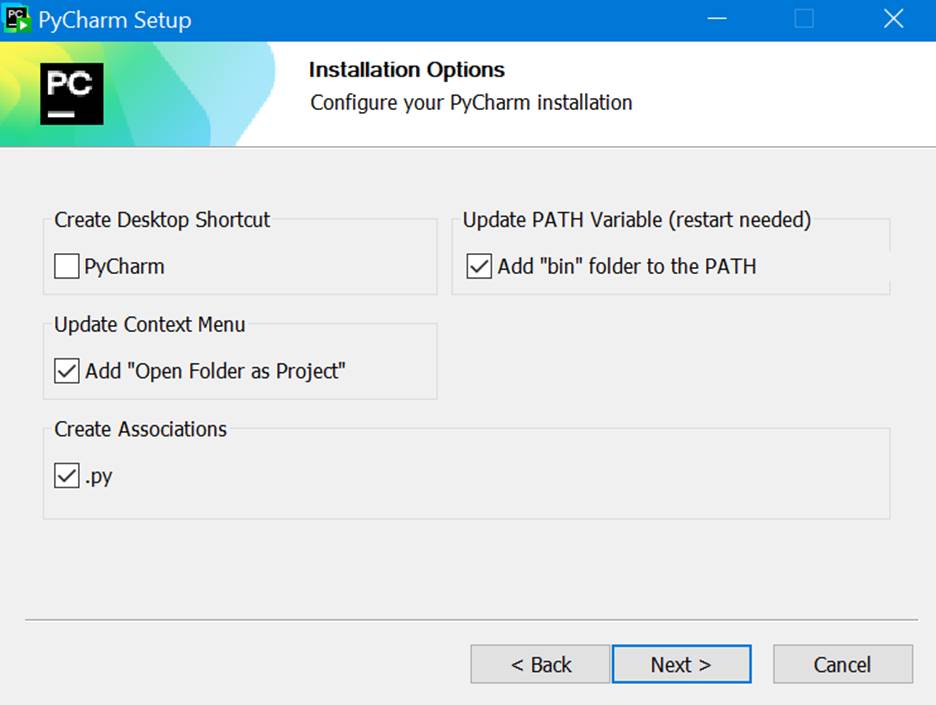
Then download and install JetBrains’ PyCharm application, Community Edition. Note in Tim’s video above, he mentions a promotion for the Professional Edition, to get three months of the Pro edition with every initial download. But I couldn’t find that. But I see that maybe more recently, JetBrains offers one month of the Pro edition with every initial download. That’s cool, so I took that. PyCharm has an integration with Hugging Face, as well as support for TensorFlow, git, PyTorch, jupyter notebooks, etc. It looks great.
I thought that it would be a good idea to set up the environment variable:
Of course, to follow the remaining content, it helps to have a working knowledge of Python, and to have Visual Studio Code installed on your station, with all needed extensions. If you’re not there yet, I recommend this written Visual Studio Code tutorial here: Getting Started with Python in VS Code.
Note that when I first installed PyCharm, it came up with the virtual environment already set up when I created a new Project. This makes life a lot easier by isolating my environment for this Project and avoiding the tricky Python dependencies that used to surface back in the old days. Thank you, new Python!
Once this is all set up, you can (to speed things up a little) set up a requirements.txt file, which is needed to configure everything for our work with the Transformers library and LangChain. Right-click on the Project name (in my case, I just named it PythonProject) and add it to the Project, then edit it to add these three lines:
transformers
langchain
langchain-huggingface
And then use pip to install all these modules into this environment:
(.venv) >pip install -r .\requirements.txt
It will run for a few minutes, and finally succeed. We’re almost ready to start coding, after we get our Hugging Face access token! This is a “keep them honest” way for Hugging Face to ensure that the license terms for the models are honored.
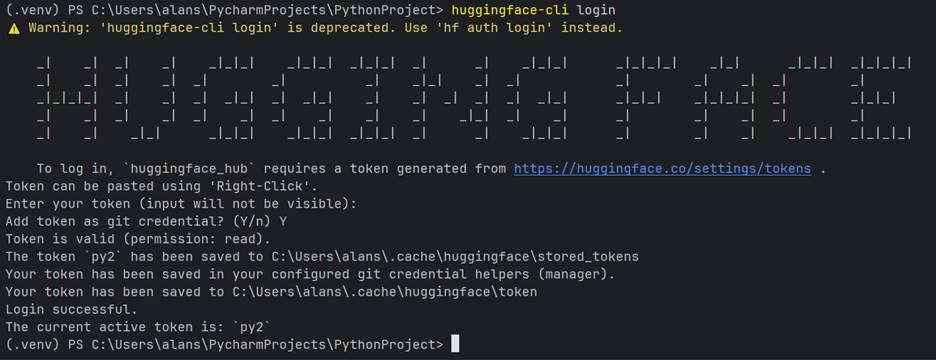
Go back into Hugging Face, click on your profile picture, and click on Access Tokens:
Then click on “Create New Token”, add in a Token name (anything you want), then hit the Read tab, and create it. Save your token in a safe place!
Then we’re ready to start the connection process. From your shell, type in:
(venv) >hf auth login
And you’ll see something like the below (you’ll have to enter your token, but it will remain invisible):
Note: for the main.py code below in Tim’s video, PyCharm compiled it like a charm:
from transformers import pipeline model = pipeline("summarization", model="facebook/bart-large-cnn") response = model("text to summarize") print(response)
However, when I tried to run it, unlike in Tim’s video, it failed with the following error messages:
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
Traceback (most recent call last):
File "C:\Users\alans\PycharmProjects\PythonProject\main.py", line 3, in <module>
model = pipeline("summarization", model="facebook/bart-large-cnn")
File "C:\Users\alans\PycharmProjects\PythonProject\.venv\Lib\site-packages\transformers\pipelines\__init__.py", line 1018, in pipeline
if isinstance(dtype, str) and hasattr(torch, dtype):
^^^^^
NameError: name 'torch' is not defined
Process finished with exit code 1
Apparently, we also need to download the NVIDIA CUDA toolkit (and driver) to use the GPU on my PC and pull in the PyTorch files. Go to https://developer.nvidia.com/cuda-downloads and initiate the download.
You MUST restart PyCharm for PyTorch to become visible, and to run the model.
Then, in the Terminal window, type in:
nvcc -- version
And in my case, I saw:
(.venv) PS C:\Users\alans\PycharmProjects\PythonProject> nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2025 NVIDIA Corporation Built on Wed_Aug_20_13:58:20_Pacific_Daylight_Time_2025 Cuda compilation tools, release 13.0, V13.0.88 Build cuda_13.0.r13.0/compiler.36424714_0
Note that I have version 13.0 of the tools. So, this is used in the next step installing PyTorch:
But this didn’t work! Apparently, as of the time of writing, this version of the Cuda compiler driver isn’t supported with PyTorch. I got this error message from pip:
Looking in indexes: https://download.pytorch.org/whl/cu130
ERROR: Could not find a version that satisfies the requirement torch (from versions: none)
ERROR: No matching distribution found for torch
I then decided to go with cu128 of the driver, keeping my fingers crossed:
Then, it’s a simple matter of running my program, and the output is below:
Xet Storage is enabled for this repo, but the 'hf_xet' package is not installed. Falling back to regular HTTP download. For better performance, install the package with: `pip install huggingface_hub[hf_xet]` or `pip install hf_xet`
Device set to use cuda:0
Your max_length is set to 142, but your input_length is only 5. Since this is a summarization task, where outputs shorter than the input are typically wanted, you might consider decreasing max_length manually, e.g. summarizer('...', max_length=2)
[{'summary_text': 'CNN.com will feature iReporter photos in a weekly Travel Snapshots gallery. Visit CNN.com/Travel each week for a new gallery of snapshots. Please share your best shots of the U.S. with CNN iReport. Send your best photos of the United States to jennifer.smith@dailymail.co.uk.'}]
There’s so much more to write about in this part of my research, but I’ll save the remainder for an upcoming article, where I’ll cover some of the advanced capabilities provided by LangChain, and start closing in on model fine-tuning.
In this article, I explored ways to extend my LLM with knowledge specific to analyzing Intel Processor Trace.
“To me the question is what happens next. And there are three things that are happening this year. The first is infinite context-window.”
– Eric Schmidt, Ex-Google CEO
Source: The 7 Things Everyone Needs to Know About AI Right Now: Superintelligence
In Part 1 of this series, I introduced the concept behind this project: to fine-tune an open-source LLM to process massive amounts of Intel Processor Trace. This has the potential to apply to many use cases: at-scale bug triage, codebase vulnerability scans, malware detection at the point of execution in RAM, and many others.
As such, I’ll chronicle the journey of discovery as I develop this solution over many months. I’ll need to become a bit of an SME for LLMs, and combine that with my current knowledge of x86 architecture, UEFI, and OS internals.
In this article, I’ll cover the following topics:
Simplify my Python coding environment
Parameters versus Tokens – a short description
Using a Modelfile to customize LLMs – first steps
Simplifying Python Coding
I ended Part 1 with writing some Python code that connects with a local LLM, delivers a payload (the prompt) via an HTTP POST, and prints out the response. It’s pretty low-level, complex code. You can simplify this code by using the ollama Python package, obtaining that module via:
>pip3 install ollama
And then the code becomes much simpler:
import ollama
#Initialize the Ollama client client = ollama.Client()
For now, I’ll continue the development on my local hardware, so this will be the approach for a while. I may have to change my strategy when I move to Google Colab or some other platform going forward. We’ll see.
Parameters versus Tokens
Before continuing the description of the fine-tuning process, I’ll take a detour into two very important LLM concepts: tokens and parameters. While this article is not an LLM tutorial, understanding these basics is essential for adapting an LLM to specific tasks, such as interpreting instruction execution traces in UEFI.
To put it simply, tokens are the basic building blocks of text that an LLM reads and generates. They are the model’s “words” or “letters.” A token can be a single word, a part of a word, a punctuation mark, or even a space. For example, the sentence “I love my dog” might be broken down into the tokens: [“I”, ” love”, ” my”, ” dog”].
Parameters, on the other hand, are the model’s knowledge and learned relationships. They are the numerical values (weights and biases) that the model adjusts during its training to become more accurate. Think of parameters as the “neural connections” in the model’s brain; I like that analogy.
A good way to compare the two is in this table:
Aspect
Tokens
Parameters
What they are
The units of text being processed
The model’s internal knowledge and weights
Measurement
Counted per interaction (input & output)
A fixed, static number for a specific model
Function
The “what” of the conversation (input/output)
The “how” of the model’s intelligence
Analogy
The words you speak and hear
The knowledge in your brain
For tokens and parameters, in general, the larger the better. We often talk about the LLM’s “token context window” as a key means by which a model can retain “in memory” massive amounts of data that we send it; retaining earlier parts of the data without losing context.
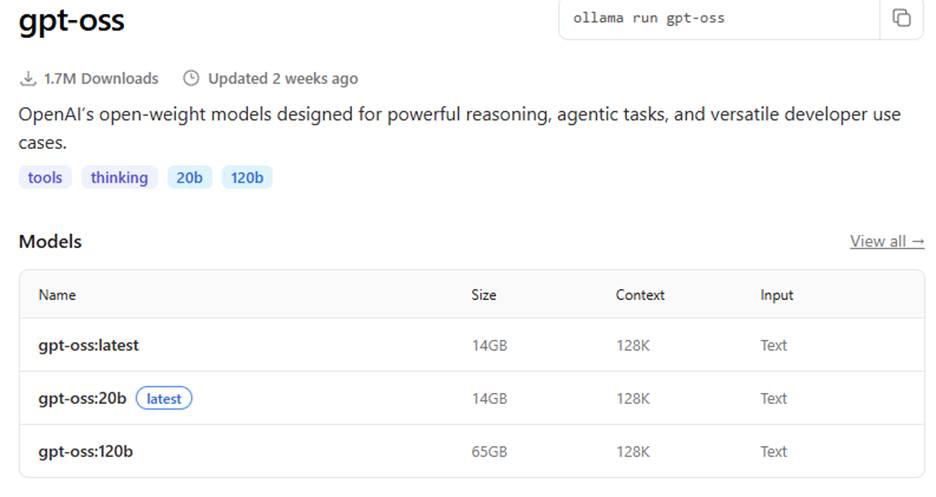
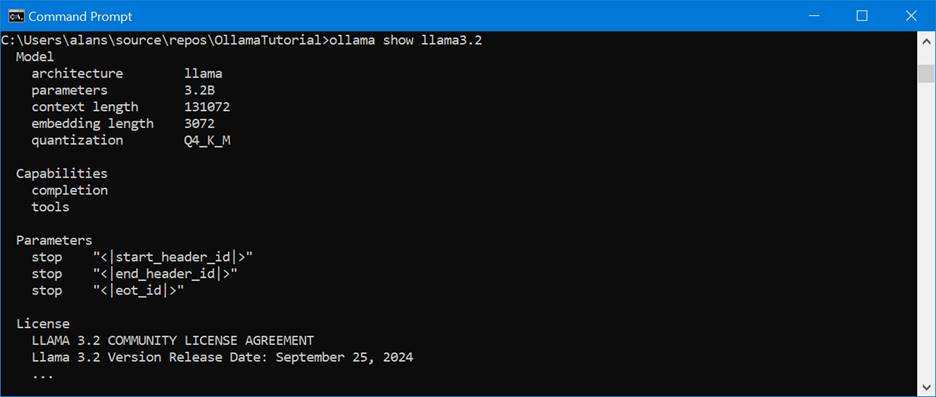
Determining the number of parameters of any given LLM can easy. It’s a fixed characteristic of the model. If you’re working with https://ollama.com/search, you’ll see it’s sometimes displayed in the description of the model; in this case, gpt-oss has two versions available, one with 20 billion parameters, and a larger one with 120 billion parameters:
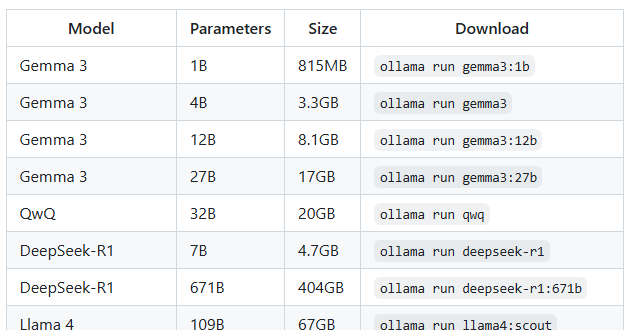
But as noted in the ollama GitHub repository, https://github.com/ollama/ollama, the bigger the model, the more RAM and disk space it’s going to take. Here are some examples:
And further, you should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
Since my local PC is a 16-thread AMD Ryzen 7 1700X CPU, 16 GB RAM, NVIDIA GeForce GTX 1060 with only 6GB VRAM, I’ll need to stick with models that have significantly fewer than 7B parameters.
Determining the context window can also be found by accessing the model repository, for example:
Or once you’ve loaded the model onto your local machine, the “ollama show <model_name> will display it as well:
Of the models that I worked with in Part 1, here’s a summary table of their tokens and parameters:
Model
Context
Parameters
mistral
32,768
7.2B
llama2
4,096
6.7B
llama3.2
131,072
3.2B
Keep in mind that the context window represents the maximum number of tokens that can be accommodated in a single interaction; including the prompt and its response. This makes sense, based on what I’ve learned about LLM tokenizer design.
Uploading and analyzing an 8 GB / 107 M-line .txt in one go isn’t possible in a single ChatGPT Plus session.
ChatGPT file uploads have a hard per-file cap of 512 MB and text/doc uploads are limited to ~2 million tokens per file (far smaller than your 8 GB trace). The blocking issue is the per-file 512 MB and 2M-token caps, which apply broadly—not just Plus. Pro/Enterprise mainly increase file count/quota, not the single-file size/token limit.
My current context window is about 128k tokens (roughly 400–500 pages of text). That’s the maximum amount of text I can keep “in working memory” at once when analyzing a file or conversation.
Very interesting. For now, I’ll focus on the token context window as a key aspect that I want to increase in size. Since I’m using an open-source model on my local PC, I’m looking for the largest context window that will fit into its constrained space. In an upcoming article, I’ll refer back to Arthur Rasmusson’s use of Paged Attention over RDMA as a means to expand the context window for Intel PT.
Here’s an important caveat: even though the context window may be quite large, the ollama platform may default it to be lower (often 2,048) to save VRAM. For customization, you will want to tune this; see the next section.
Using a Modelfile to customize LLMs
One of the means of customizing an LLM in the ollama platform is with the use of a Modelfile. This is a little text file that can modify an existing base model and creates a more specialized model.
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# set the system message
SYSTEM """
You are Mario from Super Mario Bros. Answer as Mario, the assistant, only.
"""
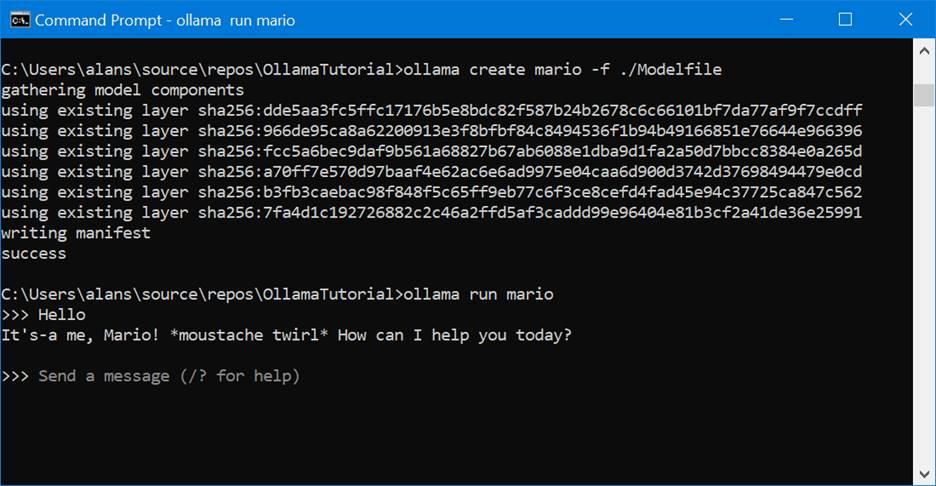
Run the following from a CMD prompt to change the model’s behavior and watch it act like Super Mario:
>ollama create mario -f ./Modelfile
>ollama run mario
>>>Hello
It's-a me, Mario! *moustache twirl* How can I help you today?
This is a simple example, so let’s dive in a little deeper to see what more interesting things that we can do.
Here’s a table of attributes that can be changed within a Modelfile:
Attribute
Description
Default Value
FROM
This is the mandatory first instruction that specifies the base model to use. It tells Ollama which pre-trained model you are building upon, which can be a model from the official Ollama library (e.g., llama3:8b) or a local .gguf file path.
N/A (Required)
SYSTEM
This sets the system prompt, which is a set of instructions that the model will follow as its core programming or persona. It’s a powerful tool for defining the model’s behavior, style, and constraints (e.g., “You are a helpful coding assistant who explains concepts clearly with code examples.”).
None (models may have a built-in system prompt)
TEMPLATE
This instruction defines the full prompt template that is sent to the model. It controls how the system message, user prompt, and model response are structured. This is essential for models that require a specific format to understand the conversation flow correctly.
Varies by model
PARAMETER
This instruction allows you to set a wide range of generation parameters that fine-tune the model’s behavior and output. The most common ones are: • temperature: Controls the creativity and randomness of the output. A lower value makes the model more deterministic and factual, while a higher value encourages more creative, diverse, and unexpected responses. • top_p: Defines a cumulative probability cutoff for selecting the next token. A lower value selects from a smaller, more focused set of tokens, leading to more conservative responses. • top_k: Reduces the probability of generating “nonsense” by limiting the model’s choice to only the k most likely tokens at each step of generation. For example, if top_k is 10, the model will only choose from the 10 most probable next words. • repeat_penalty: Penalizes words that have appeared recently in the conversation. A higher value strongly discourages repetition, which is useful for preventing the model from getting stuck in a loop.
This instruction is used to apply a LoRA (Low-Rank Adaptation) adapter to the base model. LoRAs are small, fine-tuned files that can add a specific skill or knowledge set (e.g., a specific writing style or technical expertise) to a model without requiring you to retrain the entire model.
None
LICENSE
This is a metadata instruction that allows you to specify the legal license under which your custom Modelfile and the resulting model are released. This is important for ensuring proper usage and distribution.
None
STOP
This attribute defines one or more stop sequences. When the model generates any of these specific strings, it will immediately stop generating a response, which is crucial for managing conversation turns and avoiding unnecessary output.
Varies by model (e.g., \n[INST], `\n<
MESSAGE
This instruction allows you to add pre-defined messages to the model’s history. You can use this to establish a specific conversational pattern or to pre-load a context for the model to work from before the user even starts chatting.
None
The PARAMETER and ADAPTER attributes are the most interesting ones in the context of this article.
For completeness, here’s a complete list of generation parameters (hyperparameters) that are supported by PARAMETER within Modelfiles, with a brief explanation of what each one does:
mirostat: Enables Mirostat sampling, an alternative to top_p and top_k. It is designed to control perplexity, balancing the coherence and randomness of the output. The value can be 0 (disabled), 1 (Mirostat), or 2 (Mirostat 2.0).
mirostat_eta: A learning rate parameter for Mirostat sampling. It influences how quickly the algorithm adjusts to the generated text. A higher value makes the model more responsive to feedback, while a lower value makes adjustments more slowly.
mirostat_tau: A target perplexity parameter for Mirostat. It controls the balance between coherence and diversity in the output. A lower value leads to more focused and coherent text.
num_ctx: Sets the size of the context window in tokens. This determines how much of the previous conversation or prompt the model “remembers” when generating its next response.
num_gqa: The number of Grouped-Query Attention (GQA) groups in the transformer layer. This parameter is required for some model architectures and is used to optimize performance.
num_gpu: Specifies the number of layers of the model to offload to the GPU(s) for accelerated computation. Setting it to 0 will force the model to run on the CPU.
num_predict: The maximum number of tokens to predict and generate in a single response. A value of -1 allows for infinite generation, and -2 fills the entire context window.
num_thread: Sets the number of threads used for computation. By default, Ollama automatically detects the optimal number for your system’s performance.
repeat_last_n: Defines how far back (in tokens) the model should look to apply the repetition penalty. A value of 0 disables the penalty, and -1 looks back at the entire context.
repeat_penalty: A multiplier that penalizes tokens that have appeared recently in the output. A higher value (e.g., 1.5) will more strongly discourage repetition.
seed: Sets the random number seed for generation. Using a specific seed ensures that the model will produce the exact same text for the same prompt, which is useful for debugging and reproducibility.
temperature: Controls the creativity and randomness of the model’s output. A value of 0 makes the output deterministic and factual, while a higher value leads to more diverse and creative responses.
tfs_z: Stands for Tail Free Sampling. This is a method to reduce the impact of less probable tokens. A higher value reduces this impact more, while a value of 1.0 disables it.
top_k: Limits the pool of potential next tokens to the k most likely ones. This helps prevent the model from generating random or nonsensical text.
top_p: A more dynamic alternative to top_k. It selects the smallest set of tokens whose cumulative probability exceeds the value of top_p. This balances diversity and quality.
min_p: An alternative to top_p that ensures a balance of quality and variety by setting a minimum probability for a token to be considered, relative to the most likely token.
Note the num_ctx generation parameter. We’ll need to use that.
I’ll demonstrate the use of the PARAMETER and ADAPTER features in an upcoming article.
I’ll also cover the SYSTEM feature in the next article, as I modify the model’s behavior to act like an x86 and Windows internals expert (with some forthcoming training from me, of course).
As a final note, I should mention that Arthur Rasmusson suggested testing my LLM with TensorRT-LLM and using the KVCacheTransferManager. Since the ultimate goal of this project is to train an LLM to process huge amounts of Intel Processor Trace, this seems like a good direction. TensorRT-LLM is an NVIDIA open-source library that accelerates LLM inference, and KvCacheTransferManager, a memory management system for efficient handling of large token context windows, is a core part of it.
Also, Arthur mentioned that it might be possible to run NVIDIA’s GPUDirect Storage on the RTX 1060 in my aging workstation – this is a mechanism that expands limited VRAM memory via a direct pathway between it and external memories, which will be essential to create the massive context window I’ll be needing for Intel Processor Trace – how cool would that be.
This is going to take some study on my part, as these tools aren’t for the faint of heart, but I’m looking forward to it.
In prior articles and in a recent webinar, I’ve covered the use of AI for UEFI and OS kernel trace analysis. This is a groundbreaking and novel approach for code coverage research, with many applications and potential use cases: at-scale bug triaging, codebase vulnerability scans, firmware/OS performance optimization, and many others. In this article, the first of a series, I’ll chronicle my journey learning the underlying technology of LLMs, and how that leads to a working prototype for massive trace analysis.
We’ll start at the beginning…how did this concept come about, and step-by-step how to do this independently, if you’d like to follow in these footsteps. A knowledge of basic x86 architecture, UEFI, Windows and Linux internals, and LLM technologies will help in understanding, but as usual I’ll write for beginners.
@IvanRouzanov and I were speaking one day, and the topic of Intel Processor Trace (Intel PT) came up. For those who may be unfamiliar with it, this is a debugging feature, inherent in Intel CPUs, that allows for near-real-time instruction execution trace. For a short description, the following article is a good reference: Using ChatGPT on the Windows Secure Kernel with Intel Processor Trace. For a fuller description of Intel PT, have a look at the eBook here (note: requires registration on the ASSET website): Guide to Intel Debug and Trace. And finally, this Prelude Security paper by Matt Hand, Connor McGarr and others shows how Intel PT can be used in cybersecurity: Closing the Execution gap: Hardware-Backed Telemetry for Detecting Out-Of-Context Execution.
Ivan and I discussed some of the inherent power of Intel PT, and also some of its limitations: it can trace millions of lines of executed code at a super-granular level, but consuming that massive amount of raw data and deriving actionable insights is a slog. Unless you have a deep understanding of, for example, x86 architecture and Windows internals, looking for a bug or vulnerability in all that code takes a seasoned engineer with decades of experience. And doing visual analysis – with pareto charts, histograms, scatter plots, and the like – on this quantity of data requires custom code that doesn’t really exist.
As an example, look at this excerpt of Intel PT code, captured in the Windows kernel, to get an idea:
Do you get the picture? There is meaning here, but it’s not visual, and it is difficult to comprehend except by subject-matter experts. And this is just over a dozen lines of assembly language code. Some of our largest Intel PT captures exceeded 300 million lines of code. And we are just getting started.
It struck Ivan and I that, although this amount of data was beyond human comprehension, AI might be able to give us insights. And that’s how this journey began.
Our first step was to use a commercially available, closed-source LLM and GPT, and we picked ChatGPT 4o. At the time of this writing, this is the most advanced reasoning model. And we started simply; we just collected a bunch of Intel PT, and fed it into the model, to see what it could make of it.
The results were surprisingly good, but not perfect. The following articles cover in-depth reports on the good and not-so-good results:
This research went on for several months, as we worked with the model and learned how to interact with it to get the best results. Through much trial and error, we learned to spot the more obvious errors/hallucinations and correct them; for example, even though ChatGPT’s knowledge base included the renowned and deeply technical Intel Software Developers Manual, its training introduced errors: it made basic mistakes like misinterpreting MSR addresses. Over time, it seemed that the accuracy of its analysis improved.
Our project culminated in a webinar that was presented on July 15, 2025 (note: requires registration):
After much experimentation, it became obvious that we were bumping into a ceiling in terms of ChatGPT’s ability to hold all of the trace data in memory, and thus accurately triage the source of the Windows Blue Screen of Death (BSOD) that we induced. Collecting and analyzing huge amounts of Intel PT was exceeding even the most capable closed-source, commercial models. To do better, there needed to be a means of training the model to learn from previous traces, to enhance its accuracy for analyzing specific trace contexts; for example, that of UEFI, versus Windows (the normal kernel, secure kernel, and userland applications), versus other code.
It was at this point that I connected with @ArthurRasmusson, the creator of Paged Attention over RDMA. I’ll delve into this technology in a future article in the series, but if you’re interested, I’d recommend reviewing his article Lessons Learned Scaling LLM Training and Inference with Direct Memory Access (DMA): Part 1. And if you find that article fascinating, even better is his video presentation at GTC 2025. The essence of his recent work is that we need to supercharge LLM inferencing with massive amounts of paged virtual memory if we’re ever going to analyze massive codebases.
It was for this reason that I decided to dive into exploring the development of a model trained specifically to analyze traces for Windows. Although using a closed-source model would probably be more performant in the short-term, I decided to start with an open-source model, run locally, as this represents the ultimate in flexibility, and the cost is free. And being a future optimist, I felt that AI’s capabilities, especially given Arthur’s work, will soon get this kind of power into almost everyone’s hands.
A short aside while on this topic: although I’m currently doing my research on a low-end workstation equipped with a 16-thread AMD Ryzen 7 1700X CPU, 16 GB RAM, NVIDIA GeForce GTX 1060 with 6GB VRAM (I know, it’s pretty lightweight), I’ll eventually migrate to Google Colab (https://colab.research.google.com/) where I’ll have free access to a 16GB GPU, for more heavy lifting. And even better, Arthur steered me towards an enthusiast kit – it’s only about $40K, but I can dream…. Building a16z’s Personal AI Workstation with four NVIDIA RTX 6000 Pro Blackwell Max-Q GPUs.
Thus began the learning process….
As a starting point, I acquired a couple of texts recommended by ChatGPT:
Hands-On Large Language Models by Jay Alammar and Maarten Grootendorst (O’Reilly). Copyright 2024 Jay Alammar and Maarten Peter Grootendorst, ISBN: 978-1-098-15096-9:
And Programming Massively Parallel Processors by Wen-mei W. Hwu, David B. Kirk and Izzat El Hajj (Morgan Kaufman). Copyright 2023 Elsevier, Inc, ISBN: 978-0-323-91231-0:
Reading these gave me a much better deeper understanding of how LLMs work. I’d recommend them both highly.
Next up was to study how custom LLMs are created, with the intent to optimize the model for trace analysis of UEFI and Windows code on x86 targets. This necessitated a much deeper dive into LLM architecture than was covered in the July webinar. It’s still a work-in-progress, but I’ll describe it step by step.
There are numerous online references on how to run LLMs locally, but the one I started with was Learn Ollama in 15 Minutes – run LLM Models Locally for FREE, by Tech with Tim. You can watch the video, or follow along with my steps below – I’ll elaborate on a few things that Tim glosses over as I walk through it.
Ollama allows you to run any of a slew of LLMs locally. Go to ollama.com and download, install and run the application. Tim says that that running the app just starts ollama up in the background, but on my Windows PC the application does in fact launch, and displays the following screen:
Now, if you do indeed send a message, it will first install the gpt-oss:20b LLM. This is the open-weight, open-source model by OpenAI (the creators of ChatGPT). Note that the “20b” suffix indicates that this is the 20 billion parameter model, and you’ll need in excess of 16GB RAM and quite a lot of disk storage to run this model. If you go to www.github.com/ollama/ollama, you’ll see the general statement near the bottom of the abbreviated Model Library table:
You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
So, unless you have tons of RAM and storage, don’t just enter a message right at the beginning. I did. You’ve been warned. 😊
Also, one thing I needed to do was to move the model repository off my C: drive, for lack of space. The default is in C:\users\<your user name>\.ollama. Change it by setting a new Environment Variable under System variables, OLLAMA_MODELS to D:\ollama\models, or your new directory of choice. And then restart your computer for good measure.
Download the model you want from that GitHub library (in this case I picked llama2) by opening a CMD window and typing in:
>ollama run llama2
Note that it took about 60 seconds for the llama2 prompt to appear, on my computer. It’s pretty slow – hopefully your mileage will be better.
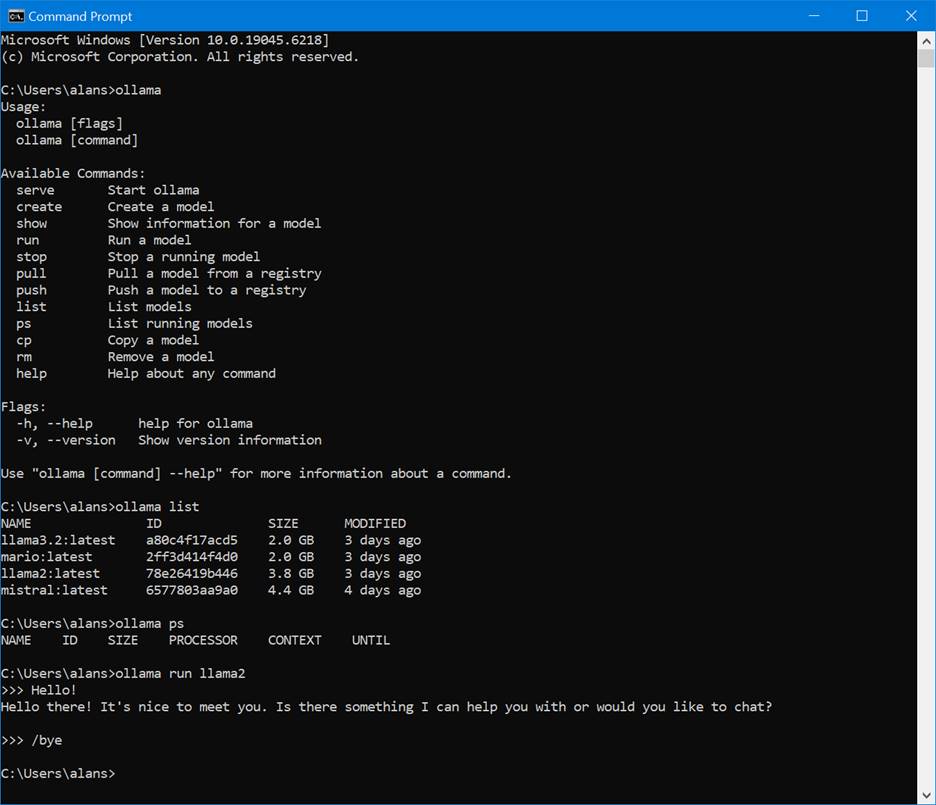
Here’s what you’ll see if you poke around with some of the commands available:
Microsoft Windows [Version 10.0.19045.6218]
(c) Microsoft Corporation. All rights reserved.
C:\Users\alans>ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
C:\Users\alans>ollama list
NAME ID SIZE MODIFIED
llama3.2:latest a80c4f17acd5 2.0 GB 3 days ago
mario:latest 2ff3d414f4d0 2.0 GB 3 days ago
llama2:latest 78e26419b446 3.8 GB 3 days ago
mistral:latest 6577803aa9a0 4.4 GB 4 days ago
C:\Users\alans>ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
C:\Users\alans>ollama run llama2
>>> Hello!
Hello there! It's nice to meet you. Is there something I can help you with or would you like to chat?
>>> /bye
C:\Users\alans>
Now, I’m going to need to access the LLM programmatically, for this project; and this is made easy with Ollama as it exposes an HTTP API on localhost. I’ll be using Python for this purpose.
It’s a good idea to run:
>ollama serve
to see the requests to the HTTP server. Cool. I like to keep this CMD window open, as it’s educational to see the traffic. Here’s a subset:
llama_model_loader: loaded meta data with 25 key-value pairs and 291 tensors from D:\ollama\models\blobs\sha256-f5074b1221da0f5a2910d33b642efa5b9eb58cfdddca1c79e16d7ad28aa2b31f (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
for line in response.iter_lines(decode_unicode=True):
if line: # Ignore empty lines
try:
# Parse each line as a JSON object
json_data = json.loads(line)
# Extract and print the assistant's message content
if "message" in json_data and "content" in json_data["message"]:
print(json_data["message"]["content"], end="")
except json.JSONDecodeError:
print(f"\nFailed to parse line: {line}")
print() # Ensure the final output ends with a newline
else:
print(f"Error: {response.status_code}")
print(response.text)
You’ll need to using the Python pip3 command to install the requests module that’s referred to on the first line of the code:
>pip3 install requests
The code is mostly self-explanatory. In this instance, I’m using the mistral model, asking the question “What is the PL/I programming language?”, and then printing out the results. I kick it off by running in a CMD window:
>python .\sample_request.py
And the output eventually appears:
Streaming response from Ollama:
PL/I (Programming Language One) is a high-level programming language that was developed in the late 1960s and early 1970s as an attempt to combine the features of several existing programming languages, such as COBOL, FORTRAN, and ALGOL. The goal was to create a single language that could be used for a variety of tasks, including business data processing, scientific computing, and systems programming.
PL/I supports a wide range of data types, including integers, floating-point numbers, strings, and complex arrays. It also features a rich set of built-in functions for mathematical operations, string manipulation, and database access. PL/I is often used in mainframe environments, particularly on IBM systems, due to its ability to work with large amounts of data efficiently.
While PL/I was once widely used, it has become less popular over time as other languages have emerged that offer more modern features and ease-of-use. However, it still remains in use in some industries and organizations where it is well-established.
Now, there are ways to avoid writing this much Python code, but for now I’m going to stay at the low-level to understand the internals of these models, as I create my own.
That’s it for now. In the upcoming episodes, I’ll dive deeper into the process whereby Intel PT data is collected, formatted, and the model fine-tuned and made ready for deployment.